
1부 6장
아싸 중간고사가 끝났다. 끝나서 기분은 좋았지만 점수가 슬프네...
오늘 정리할 부분은 분류와 회귀 작업 그리고 디중 출력 작업까지 기능한 다목적 머신러닝 결정 트리에 관해서 입니다!
왜 5장이 아니고 6장을 하는가..? -> 6장이 짧아서...
6장 모델 훈련
- 6장 결정트리
- 6.1 결정 트리 학습과 시각화
- 6.2 예측
- 6.3 클래스 확률 추정
- 6.4 CART 훈련 알고리즘
- 6.5 계산 복잡도
- 6.6 지니 불순도 또는 엔트로피?
- 6.7 규제 매개변수
- 6.8 회귀
- 6.9 축 방향에 대한 민감성
- 6.10 결정 트리의 분산 문제
뭔가 많아 보이지만 조금씩이라 생각보다 양은 많지 않다.
2징에서 캘리포니아 주택 가격 데이터셋을 완벽하게 맞추는 DecisionTreeRegressor 모델을 사용 했었는데 뭔가 살짝 기억이 난다...!
6.1 결정 트리 학습과 시각화
아래의 코드는 4장에서 했던 붓꽃 데이터셋에 DecisionTreeClassifier를 훈련시카는 코드이다. 근데 결정 트리 시각화를 곁들인...
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris(as_frame=True)
X_iris = iris.data[["petal length (cm)", "petal width (cm)"]].values
y_iris = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2, random_state=42)
tree_clf.fit(X_iris, y_iris)
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file=str(IMAGES_PATH / "iris_tree.dot"), # 경로가 책과 다릅니다.
feature_names=["petal length (cm)", "petal width (cm)"],
class_names=iris.target_names,
rounded=True,
filled=True
)
from graphviz import Source
Source.from_file(IMAGES_PATH / "iris_tree.dot") # 경로가 책과 다릅니다.

6.2 예측
위의 그림을 보고 트리가 어떻게 예측을 하는지 살펴보도록 하자. 먼저 루트 노드에서 시작을 하는데 이 노드에서 꽃잎의 길이(petal length)가 2.45cm보다 짧은지 검사를 한다. 만약 짧으면 왼쪽 (true)로 이동하고 왼쪽 노드는 리프 노드이므로 추가적인 검사를 하지 않고 class = Setosa라고 (꽃의 품종을 Setosa)라고 예측을 하게 된다.
만약 짧지 않고 길다면 오른쪽 (False)로 이동하고 추가로 petal width (꽃잎의 너비)가 1.75cm보다 작은지 검사를 한다.
만약 짧다면 (petal widht <= 1.75) Versicolor라고 예측하고 길다면 (petal widht > 1.75) Virginica로 예측하게 될 것이다.
sample 속성은 얼마나 많은 훈련 샘플이 적용되었는지, 해당 노드에 포함된 데이터 포인트(샘플)의 개수를 의미한다.
value는 각 노드에서 분류된 데이터 포인트가 클래스별로 몇 개씩 포함되어 있는지를 나타내는 값이다 즉
- 루트 노드의 value = [50, 50, 50]인 경우, 이는 이 노드에 있는 150개의 샘플이 각각 50개씩 세 가지 클래스(Iris-setosa, Iris-versicolor, Iris-virginica)로 균등하게 분포되어 있음을 의미.
- 깊이 1, 왼쪽 노드에서 value = [50, 0, 0]이라면, 이 노드에는 Iris-setosa에 해당하는 데이터 포인트만 50개가 있고, 다른 클래스에 해당하는 데이터는 없다는 의미.
- 깊이 2, 오른쪽 노드에서 value = [0, 1, 45]라는 것은, 이 노드에는 Iris-virginica 데이터가 45개, Iris-versicolor 데이터가 1개 있으며, Iris-setosa에 해당하는 데이터는 없다는 것을 의미한다.
gini는 결정 트리에서 각 노드의 혼합 정도를 나타내는 척도를 말한다. 특정 노드에 있는 샘플들이 얼마나 고르게 분포되어 있는지를 측정하며, 노드가 얼마나 순수한지(즉, 한 클래스에 얼마나 집중되어 있는지)를 보여준다.
지니 불순도가 낮을수록 해당 노드에는 특정 클래스의 샘플이 많이 포함되어 있으며, 불순도가 높을수록 다양한 클래스의 샘플이 섞여 있음을 의미한다.
\[G_i = 1 - \sum_{k=1}^{K} p_{i,k}^2\]
import numpy as np
import matplotlib.pyplot as plt
# 추가 코드 - 세부 서식 지정
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#fafab0', '#9898ff', '#a0faa0'])
plt.figure(figsize=(8, 4))
lengths, widths = np.meshgrid(np.linspace(0, 7.2, 100), np.linspace(0, 3, 100))
X_iris_all = np.c_[lengths.ravel(), widths.ravel()]
y_pred = tree_clf.predict(X_iris_all).reshape(lengths.shape)
plt.contourf(lengths, widths, y_pred, alpha=0.3, cmap=custom_cmap)
for idx, (name, style) in enumerate(zip(iris.target_names, ("yo", "bs", "g^"))):
plt.plot(X_iris[:, 0][y_iris == idx], X_iris[:, 1][y_iris == idx],
style, label=f"Iris {name}")
# 추가 코드 - 이 섹션에서는 그림 6-2를 아름답게 꾸미고 저장합니다.
tree_clf_deeper = DecisionTreeClassifier(max_depth=3, random_state=42)
tree_clf_deeper.fit(X_iris, y_iris)
th0, th1, th2a, th2b = tree_clf_deeper.tree_.threshold[[0, 2, 3, 6]]
plt.xlabel("Petal length (cm)")
plt.ylabel("Petal width (cm)")
plt.plot([th0, th0], [0, 3], "k-", linewidth=2)
plt.plot([th0, 7.2], [th1, th1], "k--", linewidth=2)
plt.plot([th2a, th2a], [0, th1], "k:", linewidth=2)
plt.plot([th2b, th2b], [th1, 3], "k:", linewidth=2)
plt.text(th0 - 0.05, 1.0, "Depth=0", horizontalalignment="right", fontsize=15)
plt.text(3.2, th1 + 0.02, "Depth=1", verticalalignment="bottom", fontsize=13)
plt.text(th2a + 0.05, 0.5, "(Depth=2)", fontsize=11)
plt.axis([0, 7.2, 0, 3])
plt.legend()
save_fig("decision_tree_decision_boundaries_plot")
plt.show()
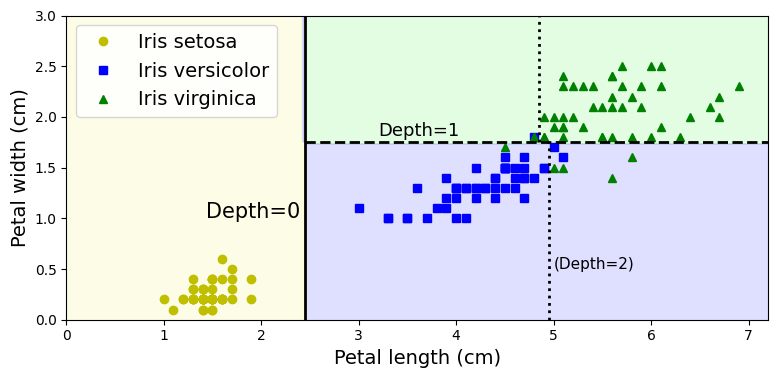
위의 코드는 결정 트리의 결정 경계를 보여준다.
6.3 클래스 확률 추정
결정 트리는 특정 샘플이 각 클래스에 속할 확률을 추정할 수 있다. 해당 샘플이 리프 노드에 도달했을 때, 특정 클래스에 속한 훈련 샘플의 비율을 통해 결정된다.
tree_clf.predict_proba([[5, 1.5]]).round(3)
tree_clf.predict([[5, 1.5]])
- tree_clf.predict_proba([[5, 1.5]]).round(3):
- 주어진 샘플에 대해 각 클래스에 속할 확률을 계산
- 출력 결과는 [0.0, 0.907, 0.093]로, 각각 Iris-Setosa, Iris-Versicolor, Iris-Virginica에 속할 확률을 의미함.
- tree_clf.predict([[5, 1.5]]):
- 주어진 샘플을 가장 높은 확률을 가진 클래스로 예측
- 결과는 [1]로, 이는 Iris-Versicolor를 의미함.
6.4 CART 훈련 알고리즘
CART(Classification And Regression Tree) 알고리즘은 결정 트리를 학습시키기 위한 방법으로, 데이터셋을 반복적으로 분할하여 최적의 결정 트리를 생성하는 알고리즘을 말한다.
처음에 데이터를 왜 나누는지 이해가 안됐었는데, 데이터를 세분화하면서 각 노드는 더 동질적인 데이터 그룹을 형성하게 된다. 즉, 데이터가 특정 클래스에 속할 가능성이 높아지는 방향으로 나뉘기 때문에, 최종적으로 트리의 리프 노드에서 예측의 정확도가 높아진다고 한다.
CART 알고리즘은 훈련 데이터셋을 하나의 특성 \( k \)와 임계값 \( t_k \)를 사용해 두 개의 서브셋으로 나눈다. 예를 들어, petal length ≤ 2.45cm라는 조건을 기준으로 데이터를 나누는 방식등이 있다.
비용함수는 아래와 같다.
\[
J(k, t_k) = \frac{m_{\text{left}}}{m} G_{\text{left}} + \frac{m_{\text{right}}}{m} G_{\text{right}}
\]
\begin{align*}
m_{\text{left}} \text{와 } m_{\text{right}} &: \text{왼쪽과 오른쪽 서브셋의 샘플 수} \\
G_{\text{left}} \text{와 } G_{\text{right}} &: \text{각각 왼쪽과 오른쪽 서브셋의 지니 불순도} \\
m &: \text{전체 샘플 수} \end{align*}
CART 알고리즘이 훈련 세트를 성공적으로 둘로 나누었다면 같은 방식으로 서브셋을 또 나누 고 그다음엔 서브셋의 서브셋을 나누고 이런 식으로 계속 반복하면서 사용하는 코드는 아래와 같다.
- 트리의 성장을 제어하기 위해 max_depth (최대 깊이)와 같은 매개변수를 설정할 수 있으며, 이러한 매개변수는 트리가 과적합되지 않도록 제어하여 일반화 성능을 높이는 데 도움이 된다.
- 또한 min_samples_split, min_samples_leaf 등의 매개변수를 통해 분할이 이루어지기 위한 최소 샘플 수 조건을 설정할 수 있다.
6.5 계산 복잡도
예측 시 계산 복잡도
- 예측 과정: 결정 트리를 사용하여 예측을 수행할 때는, 루트 노드에서 시작하여 리프 노드에 도달할 때까지 트리를 탐색해야 한다.
- 탐색 복잡도: 결정 트리가 거의 균형을 이루고 있다고 가정하면, 트리를 탐색하는 데 필요한 복잡도는 약 \( O(\log_2(m)) \)이고 여기서 \( m \)은 데이터 포인트의 수를 의미한다.
- 이는 각 노드에서 하나의 특성값만 확인하면 되기 때문에, 예측 속도가 매우 빠른 편이다.
훈련 시 계산 복잡도
- 훈련 과정: 결정 트리를 학습할 때는 각 노드에서 데이터를 나누기 위해 모든 특성을 기준으로 분할을 시도하며, 각 특성의 가능한 임계값을 계산한다.
- 훈련 시의 전체 계산 복잡도는 \( O(n \times m \log_2(m)) \)이다.
- \( n \): 훈련 데이터셋의 샘플 수.
- \( m \): 각 노드의 샘플 수.
- 이 복잡도는 각 노드에서 가능한 분할을 모두 계산하고, 최적의 분할을 찾기 위해 반복하는 과정에서 발생한다.
이를 통해 결정 트리는 예측 시에는 빠르지만, 훈련 시에는 각 노드의 분할을 찾는 과정 때문에 상대적으로 계산 비용이 높은 것을 알 수 있다.
6.6 지니 불순도 또는 엔트로피?
지니 불순도와 엔트로피의 차이
- 기본적으로 DecisionTreeClassifier는 지니 불순도를 사용하여 노드를 분할다. 하지만, 옵션으로 엔트로피(entropy)를 사용할 수도 있다고 한다.
- 엔트로피는 정보 이론에서 유래한 개념으로, 불확실성이나 무질서함을 측정한다. 엔트로피가 낮을수록 데이터의 불확실성이 적다는 것을 의미하게 된다.
- 엔트로피는 평균 정보량을 측정하며, 모든 메시지가 동일할 때 엔트로피는 0이 된다
- \[- \frac{49}{54} \log_2\left(\frac{49}{54}\right) - \frac{5}{54} \log_2\left(\frac{5}{54}\right) \approx 0.445\]
아래는 엔트로피 식이다.
\[H_i = -\sum_{k=1}^{n} p_{i,k} \log_2(p_{i,k})\]
\[
- \frac{49}{54} \log_2\left(\frac{49}{54}\right) - \frac{5}{54} \log_2\left(\frac{5}{54}\right) \approx 0.445
\]
예시로 아까 봤던 그림에서 초록색의 엔트로피는 위와 같다.
6.7 규제 매개변수
결정 트리는 훈련 데이터에 대한 제한 사항이 거의 없어, 쉽게 과적합(overfitting)될 수 있다. 또한 결정 트리는 모델 파라미터가 미리 결정되지 않아 유연하지만, 모델이 너무 복잡해지면 과적합의 위험이 커진다고 한다. 따라서 규제 매개변수를 통해 모델의 복잡도를 제한하여 일반화 성능을 높일 수 있게 된다.
- 결정 트리는 비파라미터 모델로, 훈련 전에 파라미터 수가 고정되지 않는다. 이는 데이터를 적절히 분할하여 자유롭게 모델을 형성할 수 있는 장점이 있지만, 과적합의 위험이 크다.
- 반면,선형 모델 같은 파라미터 모델은 훈련 전 파라미터 수가 정해져 있어 유연성이 낮지만 과적합의 위험이 줄어든다는 특징이 있다.
주요 규제 매개변수
- max_depth: 트리의 최대 깊이를 제한합니다. 제한하지 않으면 트리가 깊어지면서 과적합 위험이 커집니다.
- max_features: 각 노드에서 분할에 사용할 특성의 최대 수를 지정합니다.
- max_leaf_nodes: 리프 노드의 최대 수를 제한하여 트리의 크기를 조절합니다.
- min_samples_split: 노드가 분할되기 위해 필요한 최소 샘플 수를 지정합니다.
- min_samples_leaf: 리프 노드가 생성되기 위해 필요한 최소 샘플 수를 지정합니다.
- min_weight_fraction_leaf: 전체 샘플 수에서 리프 노드에 속할 최소 비율을 설정합니다.
아직 5장은 하지 않았지만 5장에서 다룰 moons 데이터셋에서 아래의 코드를 통해서 한번 확인 해보자
from sklearn.datasets import make_moons
X_moons, y_moons = make_moons(n_samples=150, noise=0.2, random_state=42)
tree_clf1 = DecisionTreeClassifier(random_state=42)
tree_clf2 = DecisionTreeClassifier(min_samples_leaf=5, random_state=42)
tree_clf1.fit(X_moons, y_moons)
tree_clf2.fit(X_moons, y_moons)
# 추가 코드 - 이 셀은 그림 6-3을 생성하고 저장합니다.
def plot_decision_boundary(clf, X, y, axes, cmap):
x1, x2 = np.meshgrid(np.linspace(axes[0], axes[1], 100),
np.linspace(axes[2], axes[3], 100))
X_new = np.c_[x1.ravel(), x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=cmap)
plt.contour(x1, x2, y_pred, cmap="Greys", alpha=0.8)
colors = {"Wistia": ["#78785c", "#c47b27"], "Pastel1": ["red", "blue"]}
markers = ("o", "^")
for idx in (0, 1):
plt.plot(X[:, 0][y == idx], X[:, 1][y == idx],
color=colors[cmap][idx], marker=markers[idx], linestyle="none")
plt.axis(axes)
plt.xlabel(r"$x_1$")
plt.ylabel(r"$x_2$", rotation=0)
fig, axes = plt.subplots(ncols=2, figsize=(10, 4), sharey=True)
plt.sca(axes[0])
plot_decision_boundary(tree_clf1, X_moons, y_moons,
axes=[-1.5, 2.4, -1, 1.5], cmap="Wistia")
plt.title("No restrictions")
plt.sca(axes[1])
plot_decision_boundary(tree_clf2, X_moons, y_moons,
axes=[-1.5, 2.4, -1, 1.5], cmap="Wistia")
plt.title(f"min_samples_leaf = {tree_clf2.min_samples_leaf}")
plt.ylabel("")
save_fig("min_samples_leaf_plot")
plt.show()
규제가 없는 왼쪽 모델은 확실히 과대적합이며 규제를 추가한 오른쪽 모델이 일반화가 더 잘 된 것을 볼 수 있다.
실제로 테스트 셋에서도 그렇게 결과가 나온다!
6.8 회귀
결정 트리는 회귀 문제에서도 사용한다고 한다. 결정 트리는 회귀 문제에도 사용할 수 있으며, 사이킷런의 DecisionTreeRegressor를 이용해 구현할 수 있다.
이 책에서 예시로 2차 함수 형태의 데이터를 생성하고, 이를 학습하기 위해 max_depth=2로 설정한 회귀 트리를 사용한다.
from sklearn.tree import DecisionTreeRegressor
np.random.seed(42)
X_quad = np.random.rand(200, 1) - 0.5 # 간단한 랜덤한 입력 특성
y_quad = X_quad ** 2 + 0.025 * np.random.randn(200, 1)
tree_reg = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg.fit(X_quad, y_quad)
# 추가 코드 - export_graphviz()를 사용하는 방법을 이미 살펴봤습니다.
export_graphviz(
tree_reg,
out_file=str(IMAGES_PATH / "regression_tree.dot"),
feature_names=["x1"],
rounded=True,
filled=True
)
Source.from_file(IMAGES_PATH / "regression_tree.dot")

예측 결과 및 트리 구조
- 학습된 트리는 분류 트리와 비슷한 구조를 가지지만, 각 리프 노드에서 평균값을 사용해 연속된 값을 예측한다.
- 각 노드는 squared_error와 value를 표시하며, 이는 해당 노드의 평균 제곱 오차(MSE)와 예측값(리프 노드의 평균값)을 나타낸다.
tree_reg2 = DecisionTreeRegressor(max_depth=3, random_state=42)
tree_reg2.fit(X_quad, y_quad)
tree_reg.tree_.threshold
tree_reg2.tree_.threshold
# 추가 코드 - 이 셀은 그림 6-5를 생성하고 저장합니다.
def plot_regression_predictions(tree_reg, X, y, axes=[-0.5, 0.5, -0.05, 0.25]):
x1 = np.linspace(axes[0], axes[1], 500).reshape(-1, 1)
y_pred = tree_reg.predict(x1)
plt.axis(axes)
plt.xlabel("$x_1$")
plt.plot(X, y, "b.")
plt.plot(x1, y_pred, "r.-", linewidth=2, label=r"$\hat{y}$")
fig, axes = plt.subplots(ncols=2, figsize=(10, 4), sharey=True)
plt.sca(axes[0])
plot_regression_predictions(tree_reg, X_quad, y_quad)
th0, th1a, th1b = tree_reg.tree_.threshold[[0, 1, 4]]
for split, style in ((th0, "k-"), (th1a, "k--"), (th1b, "k--")):
plt.plot([split, split], [-0.05, 0.25], style, linewidth=2)
plt.text(th0, 0.16, "Depth=0", fontsize=15)
plt.text(th1a + 0.01, -0.01, "Depth=1", horizontalalignment="center", fontsize=13)
plt.text(th1b + 0.01, -0.01, "Depth=1", fontsize=13)
plt.ylabel("$y$", rotation=0)
plt.legend(loc="upper center", fontsize=16)
plt.title("max_depth=2")
plt.sca(axes[1])
th2s = tree_reg2.tree_.threshold[[2, 5, 9, 12]]
plot_regression_predictions(tree_reg2, X_quad, y_quad)
for split, style in ((th0, "k-"), (th1a, "k--"), (th1b, "k--")):
plt.plot([split, split], [-0.05, 0.25], style, linewidth=2)
for split in th2s:
plt.plot([split, split], [-0.05, 0.25], "k:", linewidth=1)
plt.text(th2s[2] + 0.01, 0.15, "Depth=2", fontsize=13)
plt.title("max_depth=3")
save_fig("tree_regression_plot")
plt.show()


왼쪽이 현재 모델의 예측이고 max_depth=3으로 설정하면 오른쪽 그래 프와 같은 예측을 얻게 된다.
회귀를 위한 CART 비용 함수
- 회귀 문제에서 CART 알고리즘은 각 노드에서 MSE를 최소화하는 방향으로 분할을 수행한다.
\[J(k, t_k) = \frac{m_{\text{left}}}{m} \text{MSE}_{\text{left}} + \frac{m_{\text{right}}}{m} \text{MSE}_{\text{right}}\]
\[\text{MSE}_{\text{node}} = \frac{1}{m_{\text{node}}} \sum_{i \in \text{node}} \left( y_i - \hat{y}_{\text{node}} \right)^2\]
\[\hat{y}_{\text{node}} = \frac{1}{m_{\text{node}}} \sum_{i \in \text{node}} y_i\]

왼쪽의 기본 예측은 훈련 세트에 크게 과대적합된 것을 확인할 수 있다. min_samples_ leaf=10으로 지정하면 오른쪽 그래프처럼 훨씬 그럴싸한 모델을 만들수 있다.
6.9 축 방향에 대한 민감성

위의 사진을 봐보자 이를 통해 알 수 있는 것은 결정 트리가 데이터의 방향에 민감하다는 점이다.
이는 결정 트리가 축에 평행한 형태의 경계를 만들어 데이터를 분류하기 때문인데, 왼쪽은 데이터셋이 축에 평행한 상태로 쉽게 분류된 예시이고 오른쪽은 데이터셋이 45도 회전한 경우로, 이 경우 결정 트리가 데이터를 분할하기 어려워한다.
이를 해결하기 위해서는
- 데이터의 방향 민감성을 해결하는 한 가지 방법으로 PCA(주성분 분석)를 통해 데이터를 회전할 수 있다고 한다.
- PCA를 사용하면, 데이터의 특성 공간을 회전하여 결정 트리가 데이터를 더 잘 학습하도록 할 수 있다고 한다.
나중에 8장에서 배운다고 하니 그냥 보기만 하자.
# 추가 코드 - 이 셀은 그림 6-8을 생성하고 저장합니다.
plt.figure(figsize=(8, 4))
axes = [-2.2, 2.4, -0.6, 0.7]
z0s, z1s = np.meshgrid(np.linspace(axes[0], axes[1], 100),
np.linspace(axes[2], axes[3], 100))
X_iris_pca_all = np.c_[z0s.ravel(), z1s.ravel()]
y_pred = tree_clf_pca.predict(X_iris_pca_all).reshape(z0s.shape)
plt.contourf(z0s, z1s, y_pred, alpha=0.3, cmap=custom_cmap)
for idx, (name, style) in enumerate(zip(iris.target_names, ("yo", "bs", "g^"))):
plt.plot(X_iris_rotated[:, 0][y_iris == idx],
X_iris_rotated[:, 1][y_iris == idx],
style, label=f"Iris {name}")
plt.xlabel("$z_1$")
plt.ylabel("$z_2$", rotation=0)
th1, th2 = tree_clf_pca.tree_.threshold[[0, 2]]
plt.plot([th1, th1], axes[2:], "k-", linewidth=2)
plt.plot([th2, th2], axes[2:], "k--", linewidth=2)
plt.text(th1 - 0.01, axes[2] + 0.05, "Depth=0",
horizontalalignment="right", fontsize=15)
plt.text(th2 - 0.01, axes[2] + 0.05, "Depth=1",
horizontalalignment="right", fontsize=13)
plt.axis(axes)
plt.legend(loc=(0.32, 0.67))
save_fig("pca_preprocessing_plot")
plt.show()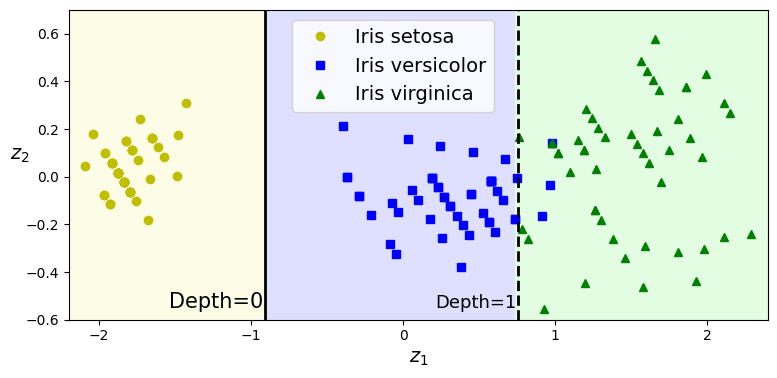
6.10 결정 트리의 분산 문제
결정 트리의 주요 문제 중 하나는 분산이 크다는 점이다.
이는 데이터셋의 작은 변화나 하이퍼파라미터의 조정으로 인해 매우 다른 모델이 생성될 수 있다는 것을 의미한다.
- 사이킷런에서 사용하는 결정 트리 알고리즘은 확률적으로 작동한다. 즉, 각 노드에서 평가할 특성 및 임계값을 무작위로 선택하는 과정이 포함될 수 있다는 뜻이된다..
- random_state 매개변수를 사용해 동일한 난수를 생성할 수 있지만, 그럼에도 불구하고 모델의 구조가 달라질 수 있는 가능성이 존재하게 된다.

위의 사진을 봐보자.
또한 위의 사진을 보자. 동일한 데이터셋에서 동일한 모델을 학습했음에도 불구하고, 생성된 결정 트리의 모델 구조가 다르게 나타날 수 있음을 보여주는 예시이다.
이는 결정 트리가 데이터의 작은 변화에 매우 민감하다는 것을 나타내며, 훈련 데이터나 하이퍼파라미터의 작은 변경이 모델의 분할 경계에 큰 영향을 미칠 수 있음을 보여다.
분산을 줄이는 방법
결정 트리의 분산 문제를 해결하기 위해서는 여러 결정 트리의 예측을 평균화하는 방법을 사용할 수 있다. 이렇게 하면 개별 트리의 분산을 줄이고, 보다 안정적인 예측을 얻을 수 있는데 이 내용은 다음 장(7장)에서 자세히 다루도록 하겠다..!
'로봇 > 인공지능, AI' 카테고리의 다른 글
| [핸즈온 머신러닝 3판] 7.앙상블 학습과 랜덤 포레스트 (1) | 2024.11.09 |
|---|---|
| [핸즈온 머신러닝 3판] 5.서포트 벡터 머신 (1) | 2024.11.03 |
| Gymnasium을 사용한 Double-inverted-pendulum (1) | 2024.10.12 |
| [핸즈온 머신러닝 3판] 4.모델 훈련 (0) | 2024.09.28 |
| [핸즈온 머신러닝 3판] 3.분류 (1) | 2024.09.20 |



