
1부 6장
오늘 정리할 부분은 다목적 머신러닝 모델 SVM이다.
5장 서포트 벡터 머신
- 5.1 선형 SVM 분류
- 5.2 비선형 SVM 분류
- 5.3 SVM 회귀
- 5.4 SVM 이론
- 5.5 쌍대 문제
무섭다 이름부터
05_support_vector_machines.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
오늘부터 코드 적는건 자제 해야겠다.. 시간도 오래걸리고 가독성도 좀 떨어지는듯,,
5.1 선형 SVM 분류

위의 그림을 확인해 보자, 그러면 확인할 수 있다시피 왼쪽 그림에서 점선은 제대로 구분을 못하고 있고, 나머지 두 선은 훈련세트에 딱 붙어있는 것을 알 수 있다.
오른쪽 그림에서 실선은 SVM 분류기의 결정 경계인데, 이 직선은 두 개의 클래스를 나누고 제일 가까운 훈련 샘플로부터 최대한 멀리 떨어져 있다고 한다. 이 말은 SVM 분류기를 클래스 사이에서 가장 폭이 넓은 도로를 찾는 것이라고 생각하면 편하다.
따라서 이를 라지 마진 분류라고 부른다고 한다.

또한 SVM은 특성의 스케일에 민감하다고 한다. 왼쪽은 스케일 조정하지 않은 것, 오른쪽은 조정한 모습이다. 보면 알 수 있다시피 조정하면 결정 경계가 더 좋아진다.
5.1.1 소프트 마진 분류
위에서 봤던 그래프들은 모든 샘플이 도로 바깥쪽에 올바르게 분류되어 있었다. 이를 하드 마진 분류라고 하는데 여기에 두 가지 문제점이 있다.
1. 선형적으로 구분되어야 함
2. 이상치에 민감한 점

위의 그림을 봐보자.
왼쪽 그림에서 처럼 만약 이상치가 다른 데이터와 섞여 있다면 하드 마진을 찾을 수 없게된다.
오른쪽 그림의 경우, 아까 봤던 결정 경계와는 다른 모습을 보여준다.
이러한 문제를 피하기 위해서 소프트 마진 분류를 사용해야 한다. 이는 좀 더 유연한 모델로 도로의 폭을 가능한 넓게 유지하는 것과 마진 오류(샘플이 도로 중간, 반대쪽에 있는 경우등) 사이에 적절한 균형을 잡는 것을 말한다.
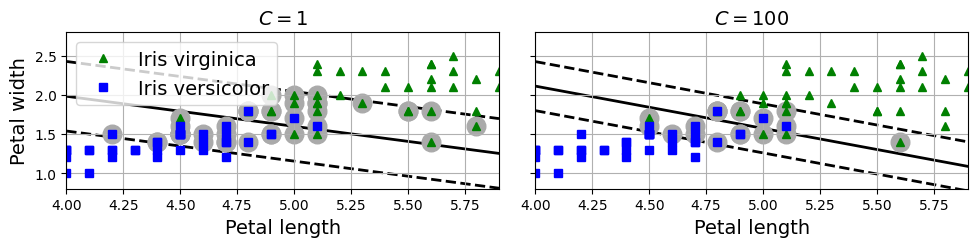
사이킷런에서 SVM 모델을 사용할 때 여러 하이퍼파라미터를 사용할 수 있는데 C를 낮게 설정하면 왼쪽과 같이 도로가 더 커지지만 많은 마진 오류가 발생한다. 반대로 높게 설정하면 오른쪽과 같이 도로가 더 좁아지는 것을 확인할 수 있다.
하지만 너무 많이 줄이면 과소적합 될 수 있으므로 주의를 해야한다고 한다.
사이킷런에서 SVM은 다음과 같이 사용할 수 있다.
import numpy as np
from sklearn.datasets import load_iris
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = load_iris(as_frame=True)
X = iris.data[["petal length (cm)", "petal width (cm)"]].values
y = (iris.target == 2) # Iris virginica
svm_clf = make_pipeline(StandardScaler(),
LinearSVC(C=1, dual=True, random_state=42))
svm_clf.fit(X, y)
X_new = [[5.5, 1.7], [5.0, 1.5]]
svm_clf.predict(X_new)
svm_clf.decision_function(X_new)
5.2 비선형 SVM 분류
선형 SVM 분류기는 좋지만 선형적으로 분류할 수 없는 데이터셋이 많다. 따라서 비선형 데이터셋을 다루어야 하는데 다루는 방법중 하나는 다항 특성과 같은 특성을 추가하는 것이다.

위의 사진을 보면 알 수 있듯이 오른쪽 그래프는 두 번째 특성 X2를 추가해서 만든 데이터셋으로 선형적으로 구분할 수 있게된다.
사이킷런으로 이를 구현하기 위해서 PolynomialFeatures 변환기와 StandardScaler, LinearSVC를 연결하여 파이프라인을 만들어 주자.
이를 moons 데이터셋에 적용할 건데 moons 데이터셋은 주로 분류 알고리즘을 테스트할 때 사용하는 샘플 데이터셋 중 하나로 이름처럼 달(Moon) 모양의 두 개의 반원형 군집으로 구성되어 있어, 비선형적인 데이터 분류 문제를 실험하기에 적합한 데이터셋이라고 한다.
# 추가 코드 - 이 셀은 그림 5-6을 생성하고 저장합니다.
def plot_dataset(X, y, axes):
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "bs")
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "g^")
plt.axis(axes)
plt.grid(True)
plt.xlabel("$x_1$")
plt.ylabel("$x_2$", rotation=0)
def plot_predictions(clf, axes):
x0s = np.linspace(axes[0], axes[1], 100)
x1s = np.linspace(axes[2], axes[3], 100)
x0, x1 = np.meshgrid(x0s, x1s)
X = np.c_[x0.ravel(), x1.ravel()]
y_pred = clf.predict(X).reshape(x0.shape)
y_decision = clf.decision_function(X).reshape(x0.shape)
plt.contourf(x0, x1, y_pred, cmap=plt.cm.brg, alpha=0.2)
plt.contourf(x0, x1, y_decision, cmap=plt.cm.brg, alpha=0.1)
plot_predictions(polynomial_svm_clf, [-1.5, 2.5, -1, 1.5])
plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
save_fig("moons_polynomial_svc_plot")
plt.show()

5.2.1 다항식 커널
다항 특성을 추가하는 것은 간단하고 모든 머신러닝 알고리즘에서 잘 작동하지만 낮은 차수의 경우 잘 표현하지 못하고 높은 차수의 경우 모델이 느려지게 된다.
이때 커널 트릭이라는 것을 사용할 수 있다. 커널 트릭은 SVM에서 고차원으로 변환한 데이터의 계산을 효율적으로 처리하는 방법으로 다항식 특성을 직접 추가하지 않고도, 마치 고차원 공간에 데이터가 있는 것처럼 계산할 수 있게 해준다. 즉, 많은 특성을 직접 계산하지 않고도 더 복잡한 경계를 만들 수 있어, 연산량이 크게 줄어드는 기적...을 볼 수 있다!
여기서 다항식 커널은 데이터를 다항식 형태로 변환하여 더 높은 차원에서 분류가 가능하도록 하는 방법이라고 한다.
아래 사진에서 왼쪽은 3차식 다항식 커널, 오른쪽은 10차식 다항식 커널을 사용한다.

5.2.2 유사도 특성
비선형 특성을 다루는 또 다른 기법은 각 샘플이 특정 랜드마크와 얼마나 닮았는지 측정하는 유사도 함수로 계산한 특성을 추가하는 방법이 있다.
유사도 특성은 특정한 기준 지점(이를 랜드마크라고 함)과 각 데이터 포인트가 얼마나 가까운지를 나타내는 값이라고 생각하면 된다.

두 랜드마크 \( x_1 = -2 \)와 \( x_1 = 1 \)을 추가하고 왼쪽그래프 처럼 유사도 함수로 \(\gamma = 0.3\)인 RBF를 사용한다 (RBF는 기준점에서 멀리 떨어진 점들은 유사도가 0에 가깝고, 가까운 점들은 1에 가까워 지게 한다.)
이제 새로운 특성을 만들어보자. 예를 들어 \( x_1 = -1 \)을 보면 첫번 째 랜드마크에서는 1만큼 떨어져있고 두 번째 랜드마크에서는 2만큼 떨어져있다.
주어진 데이터 포인트 \( x \)와 두 랜드마크 \( x_1 = -2 \)와 \( x_2 = 1 \)에 대해 RBF 함수를 사용하여 새로운 특성 \( x_2 \)와 \( x_3 \)를 계산한다.
RBF 함수의 일반식은 다음과 같다: \[ \text{RBF}(x, \text{landmark}) = \exp(-\gamma \cdot \| x - \text{landmark} \|^2) \] 여기서 \(\gamma = 0.3\)이기 때문에 계산 하면 \[ x_2 \approx 0.74, \quad x_3 \approx 0.30 \]를 얻을 수 있고 오른쪽 그래프로 나타낼 수 있다. 볼 수 있듯이 선형적으로 구분이 가능해진다..!!
5.2.3 가우스 RBF 커널
다항 특성 방식과 마찬가지로 유사도 특성 방식도 머신러닝 알고리즘에 유용하게 사용될 수 있다.
커널 트릭을 사용해 유사도 특성 을 많이 추가하는 것과 같은 비슷한 결과를 얻을 수 있는데, 가우스 RBF 커널을 사용해보자.
rbf_kernel_svm_clf = make_pipeline(StandardScaler(),
SVC(kernel="rbf", gamma=5, C=0.001))
rbf_kernel_svm_clf.fit(X, y)

위의 그래프를 봐보자.
gamma를 증가시키면 종 모양 그래프가 좁아져서 각 샘플의 영향 범위가 작아지는 모습을 확인할 수 있다. 반대로 작은 gamma 값은 넓은 종 모양 그래프를 만들며 샘플이 넓은 범위에 걸쳐 영호텔 주므로 결정 경계가 더 부드러워지게 된다.
즉 \(\gamma\)에 따라서 모델이 과대적합일 경우 감소시키고 과소적합이면 증가시켜야 한다. 이때 C 하이퍼파라미터도 함께 조절하는 것이 좋다고 한다.
5.2.4 계산 복잡도
LinearSVC의 경우 liblinear 라이브러리를 기반으로 선형 SVM을 최적화하는 알고리즘을 사용한다. 이 라이브러리는 커널 트릭을 지원하지 않지만 훈련 샘플과 특성 수에 거의 선형적으로 늘어난다고 한다.
따라서 이 알고리즘의 복잡도는 시간 복잡도: \(O(m \times n)\), 여기서 \(m\)은 샘플 수, \(n\)은 특성 수를 의미합니다.
SVC의 경우 커널 트릭 알고리즘을 구현한 libsvm 라이브러리를 기반으로 한다.
시간 복잡도: \(O(m^2 \times n) \sim O(m^3 \times n)\)의 사이이다 즉 훈련 샘플 수가 커지면 엄청나게 느려지게 된다. 하지만 특성의 수에 대해서는 특히 희소 특성(sparse feature)인 경우에는 잘 확장되는데, 희소 특성이란 각 샘플에 0이 아닌 특성이 몇 개 없는 경우를 의미한다. 이런 경우 알고리즘의 성능은 샘플이 가진 0이 아닌 특성의 평균 수에 거의 비례한다고 볼 수 있다.
이를 종합하면 SVC의 경우 중소규모 데이터셋에 적합하며, 대규모 데이터(비선형 데이터)에서는 속도가 느려질 수 있다고 한다.
SGDClassifier 클래스는 확률적 경사 하강법을 사용하여 SVM을 구현하는 것으로. 시간 복잡도: \(O(m \times n)\)으로, 큰 데이터셋에 적합하며 메모리를 효율적으로 사용한다. 또한 커널 트릭을 사용하지 않고, 하이퍼파라미터 alpha, penalty, learning_rate를 조정하여 라지 마진 분류기를 수행한다고 한다.
5.3 SVM 회귀
SVM을 분류가 아닌 회귀에 적용할 수 있다. 바로 마진 오류 안에서 두 클래스 간의 도로 폭이 가능한 최대가 되도록 하면서 제한된 도로 밖의 샘플 안에서 도로 안에 가능한 많은 샘플이 들어가도록 학습하는 것이다.
-> 말이 너무 어려워서 GPT에게 물어봄.
- SVM 회귀와 분류의 차이: SVM(Support Vector Machine)은 원래 분류 문제에서 사용됩니다. 분류에서는 두 클래스를 나누는 경계선을 찾아서, 그 경계선에서 최대한 멀리 떨어진 마진(margin)을 유지하도록 합니다. 이 마진은 두 클래스 사이의 "도로"라고 생각할 수 있습니다.
- 회귀에서의 도로(마진) 개념: 회귀 문제에서는 두 클래스 간의 경계를 찾는 것이 아니므로, "도로" 개념을 약간 다르게 사용합니다. 회귀에서는 예측 선 주변에 "도로(마진)"를 만들어 그 안에 최대한 많은 데이터 포인트가 포함되도록 학습합니다. 즉, 예측 선에서 크게 벗어나지 않는 한, 데이터 포인트가 도로(마진) 안에 들어오도록 하는 겁니다.
- SVM 회귀에서 "도로(마진) 안으로 데이터 포인트를 최대한 많이 포함"하려는 이유는 모델이 너무 민감하게 반응하지 않도록 하기 위해서입니다.
- 일반화 능력 향상: 마진(도로)을 설정하여 예측 선에서 약간 벗어나는 데이터 포인트에 대해서는 오차로 간주하지 않게 되므로, 모델이 더 단순해지고 새로운 데이터에 대한 일반화 능력이 좋아집니다. 이로써 훈련 데이터와 비슷한 패턴을 가진 새로운 데이터에도 유연하게 대응할 수 있게 됩니다.
- 마진 오류: 회귀에서 마진은 우리가 허용할 수 있는 오차 범위를 의미합니다. 이 마진 내에 데이터가 포함되면 예측에서 약간 벗어나더라도 오류로 간주하지 않습니다. 마진 바깥에 있는 포인트만 학습 과정에서 오류로 처리됩니다.
- 하이퍼파라미터 ϵ: 이 도로의 폭, 즉 마진의 넓이는 하이퍼파라미터인 ϵ으로 조절합니다. ϵ을 작게 설정하면 도로가 좁아져 예측 선에 더 민감하게 반응하고, ϵ을 크게 설정하면 도로가 넓어져 예측에서 약간 벗어난 포인트들도 큰 문제로 보지 않게 됩니다.
이 때 도로의 폭은 하이퍼파라미터 ε(엡실론)으로 조절할 수 있다.

위의 사진을 보면 알 수 있듯이 마진(도로의 폭)이 넓어지면, 허용 오차가 커지기 때문에 더 많은 데이터 포인트가 마진 내에 포함되고, 모델이 데이터를 덜 엄격하게 예측하게 되어 예측 선에서 벗어난 데이터에 대해 민감하지 않게 된다. 이렇게 되면 마진 안에서는 훈련 샘플이 추가 되어도 모델의 예측에는 영향이 없어지게 된다. 따라서 이러한 모델을 ε에 민감하지 않다 (ε-insensitive)라고 말한다.
from sklearn.svm import LinearSVR
# 추가 코드 - 이 세 줄은 간단한 선형 데이터셋을 생성합니다.
np.random.seed(42)
X = 2 * np.random.rand(50, 1)
y = 4 + 3 * X[:, 0] + np.random.randn(50)
svm_reg = make_pipeline(StandardScaler(),
LinearSVR(epsilon=0.5, dual=True, random_state=42))
svm_reg.fit(X, y)
위의 코드는 선형 SVM 회귀 코드이다. (왼쪽 그래프, 오른쪽 그래프의 경우 1.2로 바꿔야 함)

위의 사진은 비선형 회귀이다. 이를 처리하기 위해서는 커널 SVM 모델을 사용하면 되는데 2차 다항 커널을 사용한 모습이다. 여기서 왼쪽 그래프는 규제가 약간 있으며, 오른쪽 그래프는 매우 적은 모습을 확인할 수 있다(C).
from sklearn.svm import SVR
# 추가 코드 - 이 세 줄은 간단한 2차방정식 데이터셋을 생성합니다.
np.random.seed(42)
X = 2 * np.random.rand(50, 1) - 1
y = 0.2 + 0.1 * X[:, 0] + 0.5 * X[:, 0] ** 2 + np.random.randn(50) / 10
svm_poly_reg = make_pipeline(StandardScaler(),
SVR(kernel="poly", degree=2, C=0.01, epsilon=0.1))
svm_poly_reg.fit(X, y)사이킷런의 SVR을 사용해 그래프를 만들 수 있다.
또한 책에서 SVR, LinearSVR에 대해 설명한다.
- SVR: SVM의 회귀 버전으로, 커널 트릭을 사용할 수 있어 비선형 회귀 문제도 해결할 수 있습니다. 그러나 커널을 사용하는 만큼, 데이터 셋의 크기가 커지면 훈련 시간이 상당히 길어질 수 있습니다.
- LinearSVR: LinearSVR은 SVM 회귀의 선형 버전으로, 커널 트릭을 사용하지 않는 대신 훈련 시간이 데이터 셋의 크기에 선형적으로 비례합니다. 즉, 데이터 크기가 커져도 훈련 시간이 상대적으로 더 빠르게 증가하여 큰 데이터 셋에 적합합니다.
요약하면, SVR은 비선형 회귀 문제에 유용하지만 데이터 크기가 커질수록 느려지고, LinearSVR은 커널을 사용하지 않아 큰 데이터 셋에 더 효율적입니다.
5.4 SVM 이론
이 절부터는 SVM에 더 깊이 알고 싶을 때 보면 된다고 한다. (엄청 관심은 없지만.. 그래도 해야겠죠^_^)
SVM의 결정 함수는 다음과 같다. $f(\mathbf{x}) = \mathbf{w} \cdot \mathbf{x} + b$ 여기서 $\mathbf{w}$는 가중치 벡터, $b$는 편향(bias)을 뜻한다.
여기서 $f(\mathbf{x})$ > 0 이면 예측된 클래스는 양성이 되고, 반대면 음성이 된다.

우리는 도로를 가능한 넓게 만드는 가중치 벡터 $\mathbf{w}$와 $b$를 찾아야 한다. 위의 그래프를 봐보자. 알 수 있듯이 도로의 넓이는 $\mathbf{w}$를 더 작게 만들수록 커지는 것을 알 수 있다. 여기서 $b$는 도로의 넓이에 영향을 미치지 않고 위치만 이동시킨다고 한다.
또한 마진 오류도 피하는 것이 좋을 것이다. 도로의 경계를 결정 함수가 -1 또는 +1이라고 가정해보자. 위의 그래프를 통해서 보면 결정함수가 양성 훈련 샘플에서는 1보다 커야 하고 음성에서는 -1보다 작아야 한다.
위에서 말했듯이 각 샘플이 마진 밖에 위치하도록 하기 위해, SVM에서는 다음과 같은 제약 조건을 설정한다.
- 양성 클래스 \((y^{(i)} = 1)\)의 샘플은 결정 함수의 결과가 1 이상이 되도록 함.
- 음성 클래스 \((y^{(i)} = -1)\)의 샘플은 결정 함수의 결과가 -1 이하가 되도록 함.
이 조건을 다음과 같이 통합할 수 있다.
\[t^{(i)} (\mathbf{w} \cdot \mathbf{x}^{(i)} + b) \geq 1\]
따라서 이를 종합해서
하드 마진 성형 SVM 분류기의 목적 함수는
\[\text{minimize}_{\mathbf{w}, b} \quad \frac{1}{2} \mathbf{w}^\top \mathbf{w}\]
\[\text{subject to} \quad t^{(i)} (\mathbf{w}^\top \mathbf{x}^{(i)} + b) \geq 1, \quad i = 1, 2, \dots, m\]
1/2를 왜 붙이는지 궁금해서 GPT에게 물어봤다...
목적 함수에 \(\frac{1}{2}\)를 붙이는 가장 큰 이유는 미분을 단순화하기 위해서입니다.
만약 \(\frac{1}{2}\)를 붙이지 않고 \(\|\mathbf{w}\|^2\)를 최소화하려고 한다면, 미분하면 \(2\mathbf{w}\)가 나오게 됩니다.
그러나 \(\frac{1}{2}\|\mathbf{w}\|^2\)를 사용하면 미분 결과가 \(\mathbf{w}\)가 되어, 불필요한 상수 계수 \(2\)를 없앨 수 있습니다.
예를 들어, \(\|\mathbf{w}\|^2 = \mathbf{w}^\top \mathbf{w}\)라면 다음과 같은 과정이 됩니다:
미분 전:
\[\frac{1}{2}\|\mathbf{w}\|^2 = \frac{1}{2} \mathbf{w}^\top \mathbf{w}\]
이를 \(\mathbf{w}\)에 대해 미분하면:
\[\frac{\partial}{\partial \mathbf{w}} \left( \frac{1}{2} \mathbf{w}^\top \mathbf{w} \right) = \mathbf{w}\]
즉, \(\frac{1}{2}\)를 붙이면 미분했을 때 단순하게 \(\mathbf{w}\)가 되어, 수식이 더 간결해집니다.
다음은 소프트 마진 분류기의 목적 함수를 구성해보자
소프트 마진 분류기의 목적 함수를 구성하려면 각 샘플에 대해 슬랙 변수 \(\xi^{(i)} \geq 0\)를 도입해야 한다. \(\xi^{(i)}\)는 \(i\)번째 샘플이 얼마나 마진을 위반했는지 정하는데, 이 문제는 두 개의 목표를 가지고 있다.
1.마진 오류를 최소화 하기 (클래스 간의 구분을 명확히 하여, 모델의 일반화 성능을 높이기) 위해 가능한 한 슬랙 변수의 값을 작게 만드는 것
2.마진을 크게 하기 (잘못된 분류나 마진 내부로 들어오는 데이터 포인트를 줄여 모델의 분류 성능을 유지) 위해 \(\frac{1}{2} \mathbf{w}^\top \mathbf{w}\)를 가능한 한 작게 만드는 것이다..
여기에 하이퍼파라미터 \(C\)가 등장한다. 이 파라미터는 두 목표 사이의 트레이드오프를 정의한다.
\[\text{minimize}_{\mathbf{w}, b, \xi} \quad \frac{1}{2} \mathbf{w}^\top \mathbf{w} + C \sum_{i=1}^m \xi^{(i)}\]
\[\text{subject to} \quad t^{(i)} (\mathbf{w}^\top \mathbf{x}^{(i)} + b) \geq 1 - \xi^{(i)}, \quad \xi^{(i)} \geq 0\]
이 처럼 하드 마진과 소프트 마진 문제는 모두 선형적인 제약 조건이 있는 볼록 함수의 이차 최적화 문제이다. 이런 문제를 쿼드라틱 프로그래밍(quadratic programming, QP) 문제라고 부른다고 한다. (뭐야 이거)
SVM을 훈련하는 한 가지 방법은 QP 솔버를 사용하는 것이라고 한다. 또 다른 방법은 경사 하강법을 사용하여 힌지 손실(hinge loss) 또는 제곱 힌지 손실(squared hinge loss)을 최소화하는 것이라고 한다.
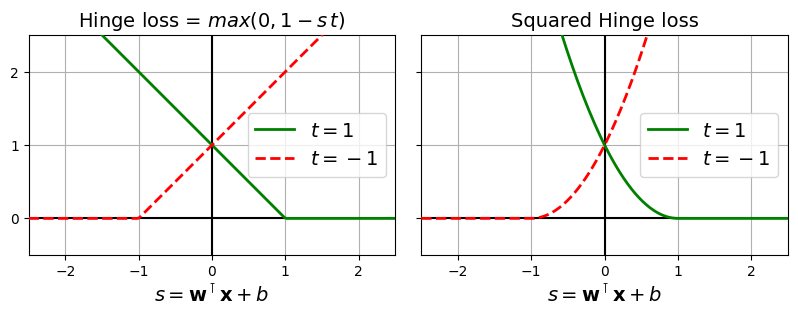
위의 그래프를 봐보자
양성 클래스 샘플 \(x\)가 주어졌을 때 \((t = 1)\) 결정 함수의 출력 \(s (s = \mathbf{w}^\top \mathbf{x} + b)\)가 1보다 크면 손실은 0이 되는 모습을 확인할 수 있다. 이는 샘플이 도로에서 벗어나 양성 클래스 쪽에 있는 경우이며, 음성 클래스 샘플 \((t = -1)\)이 주어졌을 때는 \(s \leq -1\)이면 손실이 0인 것을 볼 수 있다. 이는 샘플이 도로에서 벗어나 음성 클래스 쪽에 있는 경우이다.
샘플이 마진에서 반대로 멀어질수록 손실이 커지는 것을 볼 수 있다. (t=1 일때는 1에서 멀어지고 -1일때는 -1에서 멀어질 수록) 힌지 손실의 경우 선형적으로, 제곱 힌지 손실의 경우 이차 방정식으로 증가한다. 따라서 제곱 힌지 손실은 이상치에 더 민감하게 반응하고 데이터셋에 이상치가 없는 경우 더 빨리 수렴하는 경향이 있다. 기본적으로 LinearSVC는 제곱 힌지 손실을 사용하는 반면, SGDClassifier는 힌지 손실을 사용한다고 한다.
두 클래스 모두 loss 하이퍼파라미터를 "hinge" 또는 "squared_hinge"로 설정하여 손실을 선택할 수 있고, SVC 클래스의 최적화 알고리즘은 힌지 손실을 최소화하는 것과 유사한 솔루션을 찾는다고 한다...
(솔직히 무슨 말인지 잘 모르겠다)
5.5 쌍대 문제
무슨 말인지 잘 몰라서 일단 정리만 해놓을게요
- 원 문제(primal problem): 제약 조건이 있는 최적화 문제
- 쌍대 문제(dual problem): 원 문제와 관련된 다른 형태의 최적화 문제로, 원 문제의 제약 조건을 포함하여 동일한 해를 찾을 수 있도록 구성
일반적으로 쌍대 문제의 해는 원 문제 해의 하한 값이지만 어떤 조건히에서는 원 문제와 똑같은 해를 제공한다.
SVM에서는 원 문제보다 쌍대 문제로 변환해서 푸는 것이 유리한데, 특히, 커널 트릭을 사용하려면 쌍대 문제로 변환해야만 적용이 가능하다고 한다...!
쌍대 문제에서는 원 문제와는 다른 형태로 최적화 식이 구성된다. 쌍대 문제의 목적 함수는 다음과 같다.
\[\text{minimize}_{\alpha} \quad \frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} \alpha^{(i)} \alpha^{(j)} y^{(i)} y^{(j)} \mathbf{x}^{(i)} \cdot \mathbf{x}^{(j)} - \sum_{i=1}^{m} \alpha^{(i)}\]
\[ 제약 조건: \alpha^{(i)} \geq 0, \quad \sum_{i=1}^{m} \alpha^{(i)} y^{(i)} = 0\]
이 최적화 문제를 풀면, 최적의 \(\alpha\) 값을 찾을 수 있으며, 이를 통해 원 문제의 해를 구할 수 있게 된다.
\[\hat{\mathbf{w}} = \sum_{i=1}^{m} \alpha^{(i)} t^{(i)} \mathbf{x}^{(i)}\]
\[\hat{b} = \frac{1}{n_s} \sum_{i=1}^{m} \left( t^{(i)} - \hat{\mathbf{w}}^\top \mathbf{x}^{(i)} \right)\]
[\text{where} \quad \alpha^{(i)} > 0\]
5.5.1 커널 SVM
이 부분은 이해가 잘 안돼서 GPT 요약....
주어진 예시에서 2차원 벡터 \(\mathbf{x} = (x_1, x_2)\)는 다음과 같이 2차 다항식으로 변환됩니다:
\[\phi(\mathbf{x}) = \begin{pmatrix} x_1^2 \\ \sqrt{2} x_1 x_2 \\ x_2^2 \end{pmatrix}\]
이 변환을 통해 새로운 3차원 공간에서 데이터를 선형으로 분류할 수 있게 됩니다.
두 벡터 \(\mathbf{a}\)와 \(\mathbf{b}\)에 대해, 변환된 공간에서의 내적은 다음과 같이 계산됩니다:
\[\phi(\mathbf{a})^\top \phi(\mathbf{b}) = (\mathbf{a}^\top \mathbf{b})^2\]
이를 "다항식 커널"이라 하며, 두 벡터 간의 내적을 제곱하여 고차원 특징 공간으로 맵핑한 효과를 제공합니다.
일반적으로 사용되는 커널 함수는 다음과 같습니다:
1. 선형 커널:
\[ K(\mathbf{a}, \mathbf{b}) = \mathbf{a}^\top \mathbf{b} \]
2. 다항식 커널:
\[ K(\mathbf{a}, \mathbf{b}) = (\gamma \mathbf{a}^\top \mathbf{b} + r)^d \]
3. 가우스 RBF 커널:
\[ K(\mathbf{a}, \mathbf{b}) = \exp(-\gamma \|\mathbf{a} - \mathbf{b}\|^2) \]
4. 시그모이드 커널:
\[ K(\mathbf{a}, \mathbf{b}) = \tanh(\gamma \mathbf{a}^\top \mathbf{b} + r) \]
Mercer의 정리에 따르면, 커널 함수 \(K(\mathbf{a}, \mathbf{b})\)가 대칭이고 양정치 조건을 만족할 경우, 해당 커널을 통해 모든 샘플을 고차원 공간에 매핑할 수 있습니다. RBF 커널 등 여러 커널 함수가 이러한 조건을 충족합니다.
SVM의 예측 함수는 다음과 같습니다:
\[h_{w,b}(\phi(\mathbf{x}^{(n)})) = \hat{\mathbf{w}}^\top \phi(\mathbf{x}^{(n)}) + \hat{b} = \sum_{i=1}^m \alpha^{(i)} t^{(i)} K(\mathbf{x}^{(i)}, \mathbf{x}^{(n)}) + \hat{b}\]
이 식에서 \(K(\mathbf{x}^{(i)}, \mathbf{x}^{(n)})\)는 커널 함수이며, 서포트 벡터만을 사용하여 새로운 입력 벡터 \(\mathbf{x}^{(n)}\)와의 거리를 계산하여 예측에 활용합니다.
편향 \(b\) 계산은 다음과 같이 수행됩니다:
\[\hat{b} = \frac{1}{n_s} \sum_{i=1}^m \left( t^{(i)} - \sum_{j=1}^m \alpha^{(j)} t^{(j)} K(\mathbf{x}^{(j)}, \mathbf{x}^{(i)}) \right)
\]
여기서 \(n_s\)는 서포트 벡터의 수입니다. 커널 트릭을 사용하여 편향도 효율적으로 계산할 수 있습니다.
요약하자면, 커널 SVM은 고차원 공간에서 비선형 데이터를 선형적으로 분류할 수 있게 해주는 방법입니다. 다항식 커널이나 RBF 커널 등을 사용하여 데이터를 효과적으로 변환할 수 있으며, 이를 통해 예측과 분류의 정확성을 높일 수 있습니다.
일반적으로 선형 SVM을 쓸 때, 계산을 통해 어떤 최적의 해를 찾습니다. 그런데 커널 트릭을 사용하면 데이터를 높은 차원으로 변환해서 복잡한 데이터도 비선형적으로 분류할 수 있게 됩니다.
하지만 여기서 문제가 하나 생깁니다. 변환된 벡터 \(\phi(\mathbf{x})\)의 차원이 매우 크거나 무한이 될 수 있어서, 이를 직접 계산하는 건 불가능합니다. 그렇다면, 변환된 차원에서 계산을 하지 않고도 분류를 할 수 있는 방법}이 있을까요?
바로 이때 커널 트릭이 도움이 됩니다. 벡터들 간의 점곱으로만 계산할 수 있게 식을 바꾸면, 직접 높은 차원으로 변환하지 않아도 결과를 얻을 수 있습니다.
이 방식 덕분에, 차원이 커져도 효율적으로 분류할 수 있게 됩니다.
'로봇 > 인공지능, AI' 카테고리의 다른 글
| [핸즈온 머신러닝 3판] 8.차원 축소 (1) | 2024.11.17 |
|---|---|
| [핸즈온 머신러닝 3판] 7.앙상블 학습과 랜덤 포레스트 (1) | 2024.11.09 |
| [핸즈온 머신러닝 3판] 6.결정 트리 (0) | 2024.10.26 |
| Gymnasium을 사용한 Double-inverted-pendulum (1) | 2024.10.12 |
| [핸즈온 머신러닝 3판] 4.모델 훈련 (0) | 2024.09.28 |



