
1부 9장
9.비지도 학습
- 9.1 군집
- 9.2 가우스 혼합
우와 2개밖에 없다 그 중에 한개만 한다..
야호!!
09_unsupervised_learning.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
오늘날 대부분 사용할 수 있는 데이터는 레이블이 없다. (정답이 있으면 정말 좋았겠지만..)
따라서 비지도 학습이 필요하다. 8장에서 가장 널리 사용되는 비지도 학습인 차원 축소를 살펴봤었다. (차원 축소 비지도 학습이었어?) 이제 군집, 이상치 탐지, 밀도 추정등 다른 비지도 학습에 대해 알아보자.
9.1 군집
등산을 하다가 주변에서 버섯을 발견했다고 가정했을 때 주위에 또 다른 버섯이 있을 것이다. 보기에 비슷한 것들을 우리는 구별할 수 있는데 이 것들을 모으는 것을 군집이라고 한다!
즉, 비슷한 샘플을 구별해 하나의 클러스터 또는 비슷한 샘플의 그룹으로 할당하는 작업이다.

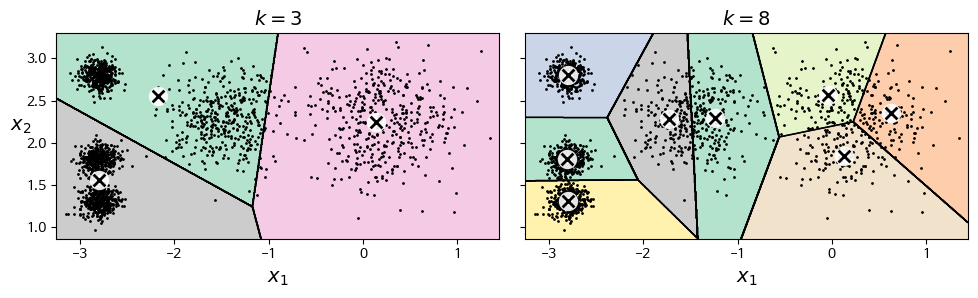
이렇게 보면 분류와 비슷해 보일 수 있지만, 분류는 레이블이 필요하다. 위의 그림을 봐보자, 왼쪽 그림의 경우 사람 눈으로도 쉽게 구별할 수 있지만 오른쪽의 경우 쉽게 구별할 수 없다.
이럴 때 군집 알고리즘을 사용하면 클러스터 세 개를 매우 잘 구분할 수 있다고 한다. (특성등을 사용해서?)
이 때 클러스터는 여러가지 모양이 될 수 있다고 한다. 클러스터에 관한 보편적인 정의는 없고 상황에 따라 다르며 알고리즘이 다르면 다른 종류의 클러스터를 감지한다고 한다. 또한 어떤 알고리즘은 센트로이드라 부르는 특정 포인트를 중심으로 모인 샘플을 찾는다고한다.
9.1.1 k-평균

위의 그림과 같이 레이블이 없는 데이터셋이 있다고 할 때, 5개의 덩어리가 보이는 것을 알 수 있다.
k-평균은 반복 몇 번으로 이러한 종류의 데이터셋을 빠르고 효율적으로 클러스터로 묶을 수 있는 간단한 알고리즘이다. 로이드 포지 알고리즘이라고 부르기도 한다고 한다..
이 데이터셋에 k-평균 알고리즘을 훈련해보자.
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# 추가 코드 - make_blobs()의 정확한 인수는 중요하지 않습니다.
blob_centers = np.array([[ 0.2, 2.3], [-1.5 , 2.3], [-2.8, 1.8],
[-2.8, 2.8], [-2.8, 1.3]])
blob_std = np.array([0.4, 0.3, 0.1, 0.1, 0.1])
X, y = make_blobs(n_samples=2000, centers=blob_centers, cluster_std=blob_std,
random_state=7)
k = 5
kmeans = KMeans(n_clusters=k, n_init=10, random_state=42)
y_pred = kmeans.fit_predict(X)여기에서 알고리즘이 찾을 클러스터 k의 개수를 정해주어야 하는데 쉬운 데이터가 아닌 이상 지정해주기 어렵다. (일단 이 데이터셋은 5개인 것을 알기 때문에 5로 지정해 준다.)
이 코드를 통해서 각 샘플은 5개의 클러스터 중 하나에 할당이 된다. 그리고 각 샘플의 레이블은 알고리즘이 샘플에 할당한 클러스터의 인덱스가 된다.
이해가 안된다면 아래를 참고
군집에서의 레이블은 알고리즘이 예측한 클러스터 번호를 의미합니다.
즉, 지도 학습(분류)에서의 레이블은 "정답(타깃 값)"이지만, 군집에서는 "샘플이 속한 클러스터의 인덱스"일 뿐입니다.
군집화는 비지도 학습이기 때문에 미리 정해진 타깃 값(정답)은 없으며, 데이터의 특성을 기반으로 클러스터를 형성합니다.
예를 들어, KMeans 알고리즘을 사용하면:
- labels_ 속성에 각 샘플이 속한 클러스터 번호가 저장됩니다.
- 이 번호는 단지 클러스터를 구분하는 ID일 뿐, 실제 정답 레이블과는 무관합니다.
정리하면:
- 분류의 레이블: 타깃 값(정답).
- 군집의 레이블: 클러스터 번호(인덱스).
y_pred
여기서 y_pred는 각 데이터 포인트가 속한 클러스터의 번호를 나타낸다.
또한 kmeans.labels_에 훈련된 샘플의 예측 레이블을 갖고 있다.
kmeans.cluster_centers_
- KMeans 알고리즘이 찾은 클러스터의 중심점(centroids)을 나타낸다.
- 다섯 개의 중심점 좌표가 배열 형태로 출력됨
import numpy as np
X_new = np.array([[0, 2], [3, 2], [-3, 3], [-3, 2.5]])
kmeans.predict(X_new)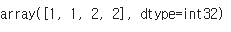
- 새로운 데이터 포인트(X_new)를 정의하고, kmeans.predict()를 사용하여 가장 가까운 클러스터를 예측할 수 있다.
- 출력된 결과는 각 데이터 포인트가 속한 클러스터 번호이다.
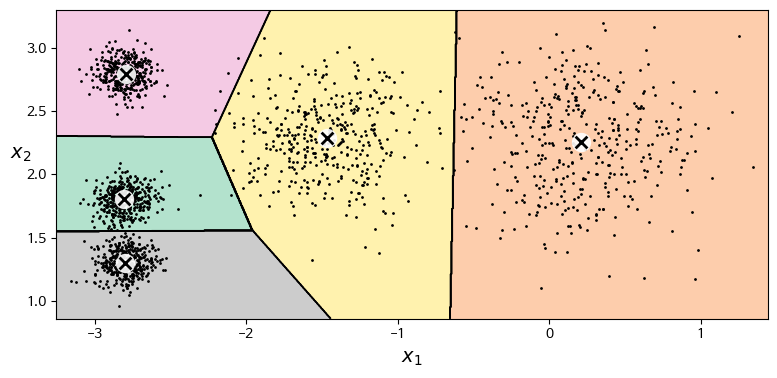
위의 그림을 보면 대부분 적절한 클러스터에 잘 할당된 것을 알 수 있다.
- 하지만 몇몇 샘플은 클러스터 경계 부근에 위치하여 잘못된 클러스터에 할당될 가능성이 있다.
- 예를 들어, 그림에서 왼쪽 위에 있는 클러스터와 가운데 클러스터의 경계 부근에 위치한 샘플이 많이 잘못 분류 되었는데,
- 이런 문제는 K-평균 알고리즘이 모든 클러스터 크기가 같다고 가정하고, 단순히 샘플과 중심점 간의 거리를 기반으로 할당하기 때문에 발생합니다.
이럴 때 책에서는 하드 군집보다 소프트 군집이 유용할 수 있다고 말한다.
- 하드 군집:
- 각 샘플을 하나의 클러스터에만 소속되도록 강제합니다.
- K-평균의 기본 방식입니다.
- 소프트 군집:
- 샘플이 여러 클러스터에 속할 가능성을 점수 형태로 나타냅니다.
- 예를 들어, 샘플과 중심점 사이의 거리를 기반으로 점수를 계산하거나 가우스 기반 확률 값을 활용합니다.
kmeans.transform(X_new).round(2)

- 이 메서드는 샘플과 각 중심점 사이의 거리를 반환한다.
- X_new에 대한 결과:
- X_new에 있는 첫 번째 샘플은 첫 번째 중심점에서 약 2.81, 두 번째 중심점에서 약 0.33만큼 떨어져 있는 것임.
- 이러한 거리는 소프트 군집이나 고차원 데이터에서 추가적인 특성으로 활용할 수 있게 된다.
이제 알고리즘이 어떻게 작동하는지 살펴보자.
1. K-평균 알고리즘의 가정
- 중심점(centroid)이 주어질 경우:
- 모든 데이터 샘플을 가장 가까운 중심점의 클러스터로 할당
- 중심점은 클러스터에 포함된 샘플의 평균 위치로 계산함.
- 중심점이 주어지지 않을 경우:
- 랜덤으로 중심점을 초기화해준다. 예를 들어, 데이터셋에서 임의로 k개의 샘플을 뽑아 중심점으로 설정해준다.
반복 과정
- 첫 단계:
- 샘플을 가장 가까운 중심점의 클러스터에 할당(레이블 지정).
- 클러스터에 속한 샘플들의 평균을 계산하여 새로운 중심점을 업데이트.
- 반복:
- 클러스터 할당 → 중심점 업데이트 과정을 반복.
- 중심점이 더 이상 변하지 않을 때까지 또는 정해진 반복 횟수에 도달할 때까지 수행.
수렴 보장
- 이 알고리즘은 중심점과 샘플 간의 평균 제곱 거리가 점진적으로 줄어들기 때문에, 제한된 횟수 안에 반드시 수렴한다.
- 하지만 수렴한 결과가 반드시 전역 최적해(global optimum)는 아니라고 한다.
- 따라서 초기 중심점 선택이 결과에 큰 영향을 미치는 것을 알 수 있다!
시각적 예시

- 랜덤 초기화:
- 중심점을 무작위로 설정.
- 처음에는 중심점이 비효율적인 위치에 있을 수 있음.
- 업데이트 과정:
- 첫 번째 클러스터 할당 후 중심점을 계산하여 이동.
- 과정을 반복하며 점진적으로 더 적합한 클러스터를 형성.
한계와 고려 사항
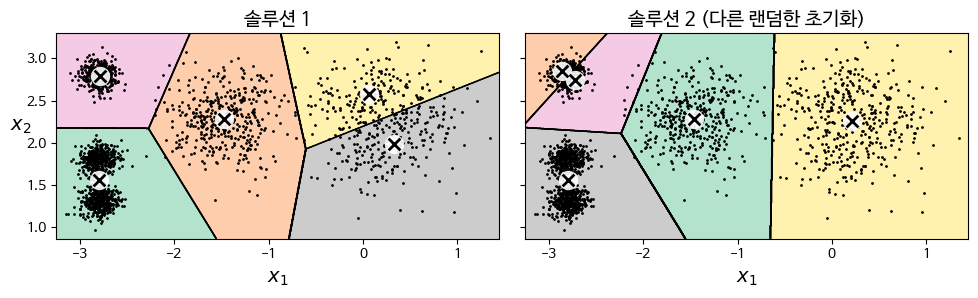
- 중심점 초기화에 따라 결과가 달라질 수 있음.
- 클러스터 개수 k를 미리 정해야 하며, 데이터셋에 적절한 k를 선택하는 것은 도전 과제
- K-평균은 클러스터 크기나 밀도가 다를 경우 부정확한 결과를 초래할 수 있습니다.
센트로이드 초기화 개선
1. 중심점 초기화 방법
고정된 초기화:
- 중심점의 위치를 알고 있다면 직접 설정할 수 있게 됨.
- 예: init 매개변수에 중심점 배열을 지정하고, n_init=1로 설정하여 한 번만 실행.
good_init = np.array([[-3, 3], [-3, 2], [-3, 1], [-1, 2], [0, 2]])
kmeans = KMeans(n_clusters=5, init=good_init, n_init=1, random_state=42)
kmeans.fit(X)
랜덤 초기화:
- 랜덤한 방식으로 중심점을 초기화한 후 여러 번 알고리즘을 실행.
- n_init 매개변수로 반복 횟수를 설정하며, 기본값은 10으로 되어 있음.
- 여러 번 실행 후 최적의 모델을 선정 할 때는 각 샘플과 가장 가까운 센트로이드 사이의 제곱 거리 합으로 이를 이너셔라고 부른다 가장 낮은 Inertia 값을 가지고 있는 모델을 고르면 된다.
kmeans.inertia_
kmeans.score(X)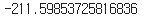
- score() 메서드:
- 사이킷런의 KMeans 클래스에는 모델의 성능을 평가하는 score() 메서드가 포함되어 있다.
- 이 메서드는 Inertia 값을 음수로 반환한다.!!!???
- 예: 만약 Inertia가 211.6이면 score() 메서드는 -211.6을 반환.
왜 음수로 반환할까?
- 사이킷런에서는 "점수가 클수록 좋은 모델"이라는 규칙을 따릅니다.
- Inertia는 값이 작을수록 좋은 모델을 의미하므로, 이를 "점수가 클수록 좋다"는 방식에 맞추기 위해 음수로 변환 한다.
- 즉, score() 메서드는 값을 음수로 바꿔서, 값이 더 작을수록(즉, 음수가 더 작아질수록) 모델이 더 좋다고 평가하도록 설계되었다고 한다.
데이비드 아서와 세르게이 바실비츠키는 2006년에 k-평균++ 알고리즘을 제안했는데, 아래와 같다.
K-평균++ 초기화 (K-Means++)
- 문제점:
- 랜덤 초기화로 인해 K-평균 알고리즘이 전역 최적해가 아닌 지역 최적해로 수렴할 가능성이 큼.
- 해결책:
- K-평균++ 알고리즘은 중심점 초기화를 개선하여 전역 최적해로 수렴할 가능성을 높임.
- 동작 원리:
- 데이터셋에서 랜덤으로 첫 번째 중심점 선택.
- 나머지 중심점은 가장 가까운 기존 중심점까지의 거리 제곱에 비례한 확률로 선택.
- k개의 중심점이 선택될 때까지 반복.
- 효과:
- 알고리즘 반복 횟수를 줄이고, 더 나은 초기화로 더 정확한 결과를 얻음.
- 사이킷런의 KMeans 클래스는 기본적으로 K-평균++ 초기화를 사용한다고 한다.
K-평균 속도 개선 (엘칸 K-평균)
- 엘칸(Charles Elkan)의 방법:
- 2013년 엘칸은 삼각 부등식(Triangle Inequality)을 활용하여 K-평균 알고리즘의 속도를 높이는 방법을 제안함.
-

삼각 부등식 - 두 점 사이의 실제 거리를 계산하지 않아도 되는 경우를 찾아 계산량을 줄임.
- 각 중심점 간의 거리를 기반으로 샘플-중심점 간 거리 계산을 효율화.
- 장점:
- 클러스터가 많거나 데이터가 대규모일 때 속도 향상.
- 단점:
- 데이터와 클러스터의 특성에 따라 속도 향상이 제한될 수 있음.
- 사용 방법:
- algorithm="elkan"으로 지정하여 엘칸 방식 사용.
MiniBatch K-Means
- MiniBatch K-Means란?:
- 데이터 전체를 사용하는 대신, 작은 미니배치를 선택해 클러스터링을 수행.
- 일반 K-평균에 비해 속도가 매우 빠름.
- 메모리에 들어가지 않는 대규모 데이터셋에도 적용 가능.
from sklearn.cluster import MiniBatchKMeans
minibatch_kmeans = MiniBatchKMeans(n_clusters=5, random_state=42)
minibatch_kmeans.fit(X)
- 장점:
- 데이터셋이 클수록 성능 향상이 두드러짐.
- 메모리 제한 문제를 해결하며, 빠른 결과 제공.
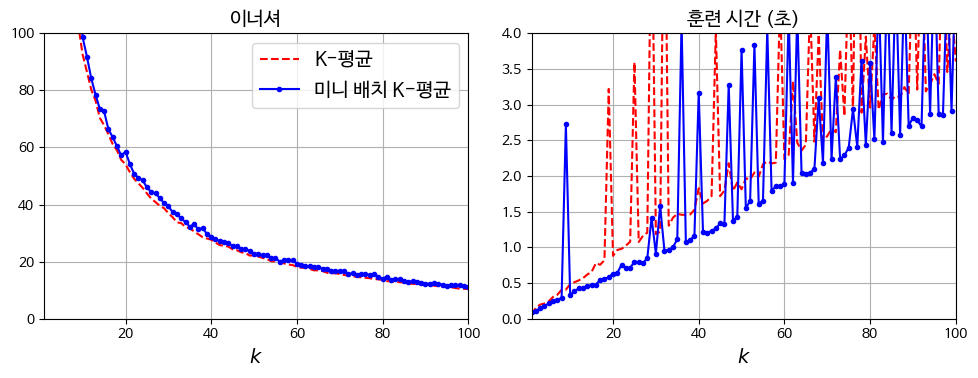
- 단점:
- 일반 K-평균보다 Inertia 값(성능 지표)가 다소 높음 (클러스터 품질이 약간 낮을 수 있음).
클러스터 수가 5보다 작거나 큰 값으로 설정된 경우 어떻게 됨?
망해요...
이를 위해서...

- Inertia는 각 샘플이 가장 가까운 중심점과의 거리 제곱 합.
- 값이 작을수록 데이터가 중심점에 잘 밀집되어 있음을 나타낸다.
- Inertia와 k의 관계:
- k가 증가할수록 Inertia는 감소.
- 그러나 k가 너무 크면 Inertia 감소 폭이 줄어드는 지점이 나타나게 된다.
- 엘보 방법:
- k와 Inertia를 그래프로 그렸을 때, Inertia 감소가 급격히 줄어드는 지점(그래프에서 팔꿈치처럼 보이는 지점)을 최적의 k로 선택하는 방법이다..
더 정확한 방법?
Silhouette 점수를 사용한 k 선택
- Silhouette 점수는 클러스터링의 품질을 평가하는 지표.
- 한 데이터 포인트가 자신의 클러스터에 얼마나 잘 속했는지를 나타냄.
- 점수는 −1에서 사이 값을 가짐:
- : 해당 샘플이 자신의 클러스터에 잘 속함.
- : 경계에 위치함.
- : 잘못된 클러스터에 속함.

from sklearn.metrics import silhouette_score
silhouette_score(X, kmeans.labels_)
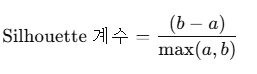
- 평균 Silhouette 점수:
- 모든 샘플의 Silhouette 점수의 평균을 구해, 최적의 k를 결정하면 됨.
실루엣 다이어그램

- 각 클러스터의 샘플들이 가지는 실루엣 점수를 시각화한 그래프
- 그래프의 높이: 각 클러스터에 포함된 샘플의 개수.
- 그래프의 너비: 해당 샘플의 실루엣 점수 (클러스터링 품질).
- 특징:
- 그래프가 넓고 균형 잡힌 클러스터일수록 좋은 클러스터링 결과를 나타냄.
2. 일 때
- 클러스터의 크기가 균일하지 않고, 일부 클러스터의 실루엣 점수가 낮음
- 문제점:
- 클러스터의 수가 너무 적어, 여러 그룹이 합쳐진 형태를 띔.
- 경계에 가까운 샘플이 많아 잘못된 클러스터링 결과를 나타냄.
3. 일 때
- 일부 클러스터가 매우 크고 다른 클러스터보다 과도하게 많은 샘플을 포함하고 있다.
- 개선점:
- 보다 더 나은 결과지만, 일부 클러스터가 불균형!
- 그래프의 일부가 파선(평균 실루엣 점수)보다 낮아 여전히 개선의 여지가 있음.
4. 일 때
- 클러스터의 크기가 균형을 이루며, 대부분의 샘플이 실루엣 점수 1.0에 가까움.
- 특징:
- 모든 클러스터의 크기가 비슷하며, 높은 실루엣 점수를 유지.
- 대부분의 샘플이 파선을 넘으며, 가장 안정적인 클러스터링 결과를 보임.
- 최적의 클러스터 개수로 판단.
5. 일 때
- 클러스터가 과도하게 세분화되어 일부 클러스터가 너무 작아짐.
- 문제점:
- 실루엣 점수가 낮아지고, 클러스터링 품질이 감소함.
9.1.2 k-평균의 한계
K-평균의 장점
- K-평균은 속도가 빠르고 구현이 간단하며 확장성이 좋습니다.
- 클러스터의 중심을 기반으로 데이터 포인트를 군집화하여 유용한 결과를 얻을 수 있습니다.
K-평균의 한계

- 최적해를 보장하지 않음:
- K-평균은 초기 중심점 선택에 따라 지역 최적해에 수렴할 가능성이 높다.
- 이를 해결하려면 알고리즘을 여러 번 실행하여 최적의 솔루션을 선택해야 함..
- 클러스터 개수 지정 필요:
- 사용자가 k 값을 미리 지정해야 하며, 최적의 k를 찾는 작업이 필요함.
- k 값을 잘못 선택하면 군집화 결과가 왜곡될 수 있다.
- 원형 클러스터에 적합:
- K-평균은 클러스터가 원형(spherical) 형태라고 가정.
- 데이터의 크기, 밀집도, 방향이 다를 경우 부적절한 결과를 초래할 수 있음.
- 예: 타원형 클러스터 데이터에서는 K-평균이 잘 작동하지 않음.
9.1.3 군집을 사용한 이미지 분할
이미지 분할(Image Segmentation)
- 정의:
- 이미지를 여러 개의 세그먼트(segment)로 나누는 작업.
- 세그먼트는 이미지 내에서 동일한 특성(색상, 형태 등)을 공유하는 영역을 나타냄.
- 분할 방식:
- 색상 분할:
- 동일한 색상을 가진 픽셀을 같은 세그먼트로 할당.
- 예: 산림 지역의 전체 면적을 계산하는 색상 기반 분할.
- 사맨틱(Semantic) 분할:
- 동일한 물체에 속하는 모든 픽셀을 같은 세그먼트로 할당.
- 예: 자율주행 자동차에서 도로와 보행자를 분리.
- 인스턴스(Instance) 분할:
- 각 개별 객체를 독립적인 세그먼트로 분리.
- 예: 여러 개의 자동차를 각각 다른 세그먼트로 분리.
- 색상 분할:
K-평균을 활용한 색상 분할
# 추가 코드 - 무당벌레 이미지 다운로드
import urllib.request
homl3_root = "https://github.com/ageron/handson-ml3/raw/main/"
filename = "ladybug.png"
filepath = IMAGES_PATH / filename
if not filepath.is_file():
print("Downloading", filename)
url = f"{homl3_root}/images/unsupervised_learning/{filename}"
urllib.request.urlretrieve(url, filepath)
import PIL
image = np.asarray(PIL.Image.open(filepath))
image.shape
첫 번째 차원의 크기는 높이, 두 번째 차원은 너비, 세 번째 차원은 색상 채널의 수를 뜻한다.
여기서 3인 경우 빨강,초록,파랑을 의미한다.
1. 이미지 데이터를 2D 형태로 변환
- 이미지는 높이×너비×색상높이 의 3차원 배열입니다.
- 예: (여기서 3은 빨강, 초록, 파랑의 RGB 값).
- 이를 전체픽셀수×3의 2차원 배열로 바꾼다.
- 즉, 각 픽셀을 RGB 색상 값으로 표현.
2. K-평균 클러스터링 적용
- K-평균 알고리즘을 사용해 픽셀 색상을 k개의 그룹으로 나누어 줌.
- 여기서는 k=8.
- 각 그룹은 평균 색상 값(클러스터 중심)을 갖는다.
3. 새로운 이미지 생성
- 원본 이미지의 각 픽셀을 가장 가까운 클러스터 중심 값으로 대체.
- 이렇게 하면 원본 이미지가 개의 색상으로 단순화된 새로운 이미지가 된다.
예제
X = image.reshape(-1, 3)
kmeans = KMeans(n_clusters=8, n_init=10, random_state=42).fit(X)
segmented_img = kmeans.cluster_centers_[kmeans.labels_]
segmented_img = segmented_img.reshape(image.shape)
- 원본 이미지와 서로 다른 값을 사용한 결과:
- 10색상: 원본과 유사하게 보임.
- 8색상: 색상이 줄어들어 단순화됨.
- 6색상 이하: 일부 디테일이 손실되며, 주요 색상만 남음.
- 2색상: 극도로 단순화되어 명확한 영역만 분리.
- 문제점:
- 가 너무 작으면 세부 정보가 사라지고, 무당벌레와 주변 영역이 같은 색상으로 합쳐질 수 있음.
9.1.4 군집을 사용한 준지도 학습
문제 상황
- 데이터의 일부만 레이블이 제공된 경우, 레이블이 없는 데이터를 활용하여 모델 성능을 높이는 방법이 필요함.
- 예제 데이터: 숫자 0~9로 이루어진 8×8 흑백 이미지. (MNIST와 유사함)
from sklearn.datasets import load_digits
X_digits, y_digits = load_digits(return_X_y=True)
X_train, y_train = X_digits[:1400], y_digits[:1400]
X_test, y_test = X_digits[1400:], y_digits[1400:]
from sklearn.linear_model import LogisticRegression
n_labeled = 50
log_reg = LogisticRegression(max_iter=10_000)
log_reg.fit(X_train[:n_labeled], y_train[:n_labeled])이 50개 샘플에 대한 레이블만 있다고 가정할 때 로지스틱 회귀 모델을 훈련하고 테스트 셋에서 모델의 정확도를 측정해 보자.
log_reg.score(X_test, y_test)
74.8%에 불과한 모습이다.. 어떻게 개선할 수 있을까?
k = 50
kmeans = KMeans(n_clusters=k, n_init=10, random_state=42)
X_digits_dist = kmeans.fit_transform(X_train)
representative_digit_idx = X_digits_dist.argmin(axis=0)
X_representative_digits = X_train[representative_digit_idx]

K-평균 군집화로 대표 샘플 추출
- 군집화 적용:
- 으로 K-평균 클러스터링을 수행.
- 각 클러스터에서 중심에 가장 가까운 이미지를 "대표 이미지"로 선택.
- 대표 이미지 50개를 사용해 모델을 다시 학습.
y_representative_digits = np.array([
1, 3, 6, 0, 7, 9, 2, 4, 8, 9,
5, 4, 7, 1, 2, 6, 1, 2, 5, 1,
4, 1, 3, 3, 8, 8, 2, 5, 6, 9,
1, 4, 0, 6, 8, 3, 4, 6, 7, 2,
4, 1, 0, 7, 5, 1, 9, 9, 3, 7
])
log_reg = LogisticRegression(max_iter=10_000)
log_reg.fit(X_representative_digits, y_representative_digits)
log_reg.score(X_test, y_test)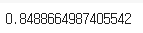
- 결과:
- 테스트 정확도가 84.9%로 상승.
- 하지만, 여전히 완벽하지 않음.
레이블 전파(Label Propagation)
- 방법:
- 대표 샘플의 레이블을 같은 클러스터 내의 모든 샘플에 전파.
- 전파된 데이터를 사용해 전체 데이터셋으로 모델을 학습.
y_train_propagated = np.empty(len(X_train), dtype=np.int64)
for i in range(k):
y_train_propagated[kmeans.labels_ == i] = y_representative_digits[i]
log_reg = LogisticRegression(max_iter=10_000)
log_reg.fit(X_train, y_train_propagated)
log_reg.score(X_test, y_test)
- 결과:
- 정확도가 89.4%로 크게 향상.
이상치 제거를 통한 성능 개선
- 방법:
- 각 클러스터에서 중심에서 멀리 떨어진 이상치를 제거.
- 중심에서 가장 가까운 샘플만 남겨 학습에 사용.
percentile_closest = 99
X_cluster_dist = X_digits_dist[np.arange(len(X_train)), kmeans.labels_]
for i in range(k):
in_cluster = (kmeans.labels_ == i)
cluster_dist = X_cluster_dist[in_cluster]
cutoff_distance = np.percentile(cluster_dist, percentile_closest)
above_cutoff = (X_cluster_dist > cutoff_distance)
X_cluster_dist[in_cluster & above_cutoff] = -1
partially_propagated = (X_cluster_dist != -1)
X_train_partially_propagated = X_train[partially_propagated]
y_train_partially_propagated = y_train_propagated[partially_propagated]
log_reg = LogisticRegression(max_iter=10_000)
log_reg.fit(X_train_partially_propagated, y_train_partially_propagated)
log_reg.score(X_test, y_test)
- 결과:
- 테스트 정확도가 90.9%로 상승.
- 전파된 데이터의 품질이 높아졌기 때문.
- 이상치를 제거한 데이터셋으로 학습한 모델의 성능은 90.9%.
- 이는 전체 데이터셋으로 학습한 모델의 성능인 90.7%를 초과함!!!!!!!!!!!!!!!
다음은 레이블의 정확도를 의미한다.
(y_train_partially_propagated == y_train[partially_propagated]).mean()

이는 전파된 레이블 중 약 97.55%가 실제 레이블과 일치한다는 뜻이다.
9.1.5 DBSCAN
DBSCAN 작동 방식:
- ε-이웃(neighborhood):
- 각 데이터 포인트의 ε 반경 내에 몇 개의 다른 포인트가 포함되는지를 계산.
- 이 반경 내에 있는 점들의 집합을 ε-이웃이라고 부름.
- 핵심 샘플(Core Sample):
- ε-이웃 내에 포함된 포인트 수가 최소 샘플 개수(min_samples) 이상인 경우, 해당 포인트를 핵심 샘플로 정의함.
- 이웃 확장:
- 핵심 샘플의 ε-이웃에 있는 점들을 같은 클러스터로 확장함.
- 이 과정에서 새로운 핵심 샘플이 발견되면 이웃 확장을 반복하며 클러스터를 형성함.
- 노이즈 판별:
- 핵심 샘플도 아니고 ε-이웃에 포함되지 않는 점들은 노이즈(-1)로 분류.
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=1000, noise=0.05, random_state=42)
dbscan = DBSCAN(eps=0.05, min_samples=5)
dbscan.fit(X)dbscan.labels_[:10]
핵심 샘플의 인덱스는 인스턴스 변수 core_sample_indices_에서 확인.
dbscan.core_sample_indices_[:10]
핵심 샘플 자체는 인스턴스 변수 components_에 저장됨.
dbscan.components_
주요 특징:
- 매개변수:
- eps: ε 반경.
- min_samples: 핵심 샘플로 정의되기 위한 최소 샘플 개수.
- 레이블:
- labels_: 각 샘플의 클러스터 레이블을 저장함.
- 레이블 값이 -1인 샘플은 노이즈로 간주함.

실험 결과 예시:
- 작은 eps 값: 적은 샘플만 클러스터에 포함되어 노이즈로 판단되는 경우가 많음.
- 큰 eps 값: 더 많은 샘플이 클러스터에 포함되어 클러스터가 잘 형성됨.
K-최근접 이웃(KNN) 모델
DBSCAN은 기본적으로 새로운 데이터에 대한 클러스터 예측을 지원하지 않으므로, KNN을 통해 다음 단계를 수행함.
DBSCAN 결과로 KNN 학습
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=50)
knn.fit(dbscan.components_, dbscan.labels_[dbscan.core_sample_indices_])- 핵심 샘플(core samples)만 사용해 KNN 모델을 학습합니다.
- n_neighbors=50: KNN이 예측할 때 사용할 이웃 수를 50개로 설정합니다.
X_new = np.array([[-0.5, 0], [0, 0.5], [1, -0.1], [2, 1]])
knn.predict(X_new)
knn.predict_proba(X_new)
y_dist, y_pred_idx = knn.kneighbors(X_new, n_neighbors=1)
y_pred = dbscan.labels_[dbscan.core_sample_indices_][y_pred_idx]
y_pred[y_dist > 0.2] = -1
y_pred.ravel()
DBSCAN의 장점:
- 클러스터의 모양과 크기에 상관없이 밀집된 영역을 잘 탐지함.
- 노이즈와 이상치를 효과적으로 처리함.
DBSCAN의 한계:
- 클러스터 간 밀집도가 너무 다를 경우, 적절한 파라미터 조합을 찾기 어려움.
- 계산 복잡도가 으로, 대규모 데이터셋에서 확장성이 제한됨.
향상된 DBSCAN:
- HDBSCAN: 다양한 밀도의 클러스터를 탐지할 수 있도록 DBSCAN을 확장한 알고리즘임.
9.1.6 다른 군집 알고리즘
1. 병합 군집(Agglomerative Clustering)
- 방법: 각 데이터를 개별 클러스터로 시작한 뒤 가까운 두 클러스터를 반복적으로 병합.
- 결과: 트리 형태의 덴드로그램으로 시각화 가능.
- 특징: 샘플 간 거리 행렬을 사용하며 대규모 데이터셋에는 비효율적.
2. BIRCH
- 목적: 대규모 데이터셋을 처리할 때 효율적.
- 방법: 데이터를 압축하여 트리 구조에 저장하고 클러스터링.
- 장점: 제한된 메모리로 대량의 데이터셋 처리 가능.
3. 평균-이동(Mean-Shift)
- 방법: 데이터의 밀집도가 높은 방향으로 중심점 이동.
- 특징: DBSCAN처럼 클러스터 수를 미리 설정할 필요 없음.
- 단점: 계산 복잡도가 높아 대규모 데이터셋에 비적합.
4. 유사도 전파(Affinity Propagation)
- 방법: 샘플 간 메시지를 교환하며 대표 샘플(예시)을 선택.
- 특징: 클러스터 수를 미리 정하지 않음.
- 단점: 계산 복잡도가 높고 대규모 데이터셋에 부적합.
5. 스펙트럼 군집(Spectral Clustering)
- 방법: 샘플 간 유사도로 그래프를 생성하고 저차원 임베딩 후 군집화.
- 특징: 복잡한 클러스터 구조에 적합.
- 제약: 클러스터 크기가 매우 다르거나 데이터셋이 클 경우 성능 저하.
'로봇 > 인공지능, AI' 카테고리의 다른 글
| [핸즈온 머신러닝 3판] 8.차원 축소 (1) | 2024.11.17 |
|---|---|
| [핸즈온 머신러닝 3판] 7.앙상블 학습과 랜덤 포레스트 (1) | 2024.11.09 |
| [핸즈온 머신러닝 3판] 5.서포트 벡터 머신 (1) | 2024.11.03 |
| [핸즈온 머신러닝 3판] 6.결정 트리 (0) | 2024.10.26 |
| Gymnasium을 사용한 Double-inverted-pendulum (1) | 2024.10.12 |



